Elon Musk continues to insist that self-driving technology is possible without supportive infrastructure and additional sensors like LIDAR. Just as human drivers primarily trust a passive optical sensing system (we call them eyes) when driving, so too can cars rely on computer vision for autonomous driving to analyze the road and drive on their own.
We have to solve passive optical image recognition extremely well in order to be able to drive in any environment and in any conditions. At the point where you’ve solved it really well, what is the point in having active optical, which means LIDAR. In my view, it’s a crutch that will drive companies towards a hard corner that’s hard to get out of.
Still, a lot of autonomous car manufacturers are developing their solutions with the use of various sensors fusion. Here you see the comparison of preferred approaches in autonomous technology development from different car makers’ standpoints.
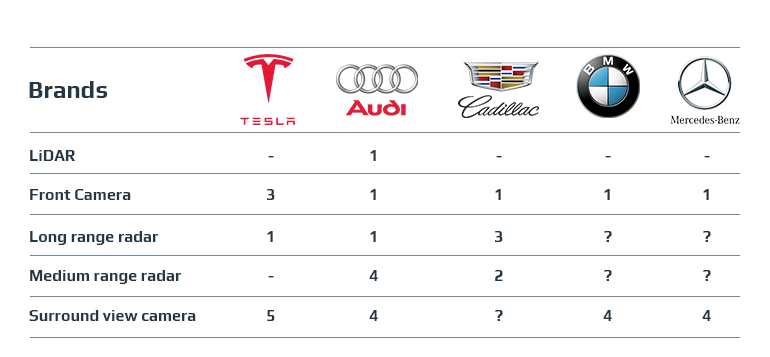
By believing in the computer vision car, Tesla’s CEO is one of only a few people who bravely promise to cross the US from coast to coast by the end of 2018 using autopilot alone. All Musk needs for that is stereo sensors to collect data, radars, and machine learning to train neural networks how to act.
I am pleased with the progress made on the neural net. It’s kind of like it goes from ‘doesn’t seem like too much progress’ to wow.
Musk’s promise is ambitious and raises a lot of questions – especially considering the recent Tesla autopilot incident that drew public attention with the screaming headline “One of the most advanced driving systems on the planet doesn’t see a freaking fire truck, dead ahead.”
Let’s figure out why Elon Musk is an adamant believer in computer vision for self-driving cars and their ability to drive the road only by seeing it just like a human driver sees.
How does computer vision in self driving cars work to see the world?

First, let’s define terms. Computer vision is the science of machines, robots, computer systems, and artificial intelligence analyzing images, recognizing objects, and acting accordingly. Computer vision in self driving cars relies on images from sensors, image processing, and deep learning to turn data into appropriate actions.
Computer vision is the science of machines, robots, computer systems, and artificial intelligence analyzing images, recognizing objects, and acting accordingly.
As for computer vision for autonomous driving, stereo sensors continuously collect images of the changing environment while driving on the road to build a picture that’s understandable for a car. But the way a car perceives visible data is quite different from the way a human perceives it. Artificial intelligence systems don’t recognize objects as people do. A person says, “here’s a tree, there’s a cat, and those are people crossing the road on the red light without any apparent reason.”
Automotive computer vision in cars doesn’t have such insights per se. A computer needs to assign specific features to objects to recognize them and understand what’s happening or what will happen in the next moment. This process of recognition includes semantic segmentation, creation of a detailed 3D map, and object detection in it. After an AI system has recognized objects on the detailed map, deep learning teaches car how to behave in a particular situation based on what it has detected. Further action is a path planning based on a virtual picture with recognized objects and assigned reactions on them.
Semantic segmentation to assign features to objects
You’ve probably seen a ton of pictures reminiscent of the image seen through a night-vision device, looking through which you could delightfully say, “Wow! I see the world as a machine.” Here you go with one more.

What we see here is called semantic segmentation or color classification for a computer vision car. This is the ability to label pixels with certain classes of objects and later assign them particular features such as the ability to move, a potential trajectory, or predictable behavioral patterns. The higher the density of pixels that an AI can label, the better its perception of the environment. Let’s look at the historical progress of pictures with labeled pixels that machines have been seeing over time.
Semantic segmentation is the ability to label pixels with certain classes of objects and later assign them particular features such as the ability to move, a potential trajectory, or predictable behavioral patterns.
1990s: 300 MHz / 80 ms / 1% density

2000s: 1 GHz / 80 ms / 20% density

2010s: 3 GHz / 2ms / >90% density

Based on data from stereo sensors, AI can pull out necessary semantics and build a 3D map of the surroundings with great accuracy and robustness. If an AI can recognize what’s in an image at this level of detail, then we have greater confidence in the ability of an autonomous car to correctly identify objects in this virtual map and further react on them faster with ADAS functions. With more accurate object recognition, computer vision for autonomous vehicles becomes much more reliable and driving itself safer, as cars can act precisely as they have been trained to a particular object or situation.
Based on data from stereo sensors, AI can pull out necessary semantics and build a 3D image of the surroundings with great accuracy and robustness.
SLAM algorithms to build a 3D picture of the unknown environment
Obtaining real-time images from sensors, a car still needs to build a virtual 3D map from them for an understanding of where it is acting now. For that, every autonomous robotic system relies on Simultaneous Localization and Mapping algorithms, or simply SLAM.
Originally, SLAM algorithms have been used to control robots, then broadened for a computer vision-based online 3D modeling, augmented reality-based computer vision applications, and finally, self-driving cars. SLAM algorithms can process data from different types of sensors such as:
- laser range sensors
- rotary encoders
- inertial sensors
- GPS
- RGB-D sensors
- LIDARs
- ultrasonic sensors
- stereo cameras
Nowadays, SLAM algorithms are the best way to keep track of the computer vision and machine learning to allow robots, cars, and drones to accurately navigate and plan their route on the basis of data from sensors. Autonomous vehicles primarily use visual SLAM (vSLAM) algorithms because of the dependence on visual images.
SLAM algorithms are the best way to keep track of the computer vision and machine learning to allow robots, cars, and drones to accurately navigate and plan their route on the basis of data from sensors.
SLAM algorithms combine unique techniques that allow to track the movement of the cameras mounted onto a car and build a pixel-based cloud map of the environment that they observe pensively or just passed. In other words, they create a virtual map of the surroundings and localize a computer vision car within this map.
The basic stages of the SLAM-created 3D map:
- Initialization – definition of a certain system of coordinates where the real-time environment will be reconstructed based on collected images
- Tracking – the collection of images with defined features depending on camera position
- Mapping – the creation of a regularly updatable 3D map based on continuously gathered images within a defined system of coordinates
There are a bunch of different SLAM algorithms that have been categorized based on the requirements. Let’s see an example of applicable SLAM algorithms that can be used for computer vision in self-driving cars.
The main requirement of an autonomous driving technology to make a car drive independently is based on collecting the data from sensors to find out car’s position and position of other visible objects around. For this, a car needs to create a map of the environment and localize itself on this map with real-time processing speed.
For autonomous vehicles, we can apply the following SLAM algorithms
LSD-SLAM – Algorithm processes data within limited target-areas with high density. It ignores textureless areas because it is difficult to estimate accurate depth data from those images.
Advantages: Recognition of street scenes in real-time and direct in-car processing. Semi-dense picture recognition.
Disadvantages: Does not consider the geometric consistency of the whole map. Reconstructed areas are limited to high-intensity gradient areas.
MonoSLAM – In this algorithm, camera motion and 3D structure of an unknown environment are simultaneously processing with an extended Kalman filter.
Advantages: Inverse depth parametrization. New features are simultaneously added to the state vector, depending on camera movement.
Disadvantages: Computational capabilities depend on the size of an environment. In large environments, a state vector increases because the number of feature points raises. For that, it is difficult to achieve real-time computation.
ORB-SLAM – It is the most complete feature-based monocular vSLAM with stereo-based recognition. It includes multi-threaded tracking, mapping, and closed-loop detection, and the map is optimized using pose-graph optimization. It computes the camera trajectory and a sparse 3D environment (in the stereo and RGB-D case with true scale). It is able to detect loops and re-localize the camera images in real time.
Advantages: It is an open source algorithm that can be used for different local environments. High stability of loop closing. It can process 30fps HD stream in real-time with 2K – 4K features simultaneously in the street scene.
Disadvantages: The dynamic environment can break stability. It cannot operate with smooth and gradient features, highly depends on density.
SVO – The tracking is done by feature point matching, the mapping is done by the direct method. The Lucas-Kanade tracker is used as feature descriptor to find correspondences.
Advantages: Precise, robust, and faster state-of-the-art method. The semi-direct approach eliminates the need for costly feature extraction and robust matching techniques for motion estimation. Algorithm operates directly on pixel intensities, which results in subpixel precision at high frame-rates.
Disadvantages: Camera motion is estimated by minimizing photometric errors related to feature points, but struggle to divide input images within a whole 3D picture.
DTAM – The tracking is done by comparing the input image with synthetic-view images generated from the reconstructed map. The initial depth map is created using stereo sensors.
Advantages: Map initialization is done by the stereo measurement. Depth information is estimated for every pixel by using multi-baseline stereo, and then, it is optimized by considering space continuity.
Disadvantages: The initial data required to build an initial map for further checks on correspondence.
Object detection to enable computer vision in self driving cars to understand what it sees
After building a 3D picture of the whole environment, the next step is to detect particular objects within this picture. As we’ve mentioned, all objects that a car sees are assigned features based on semantic segmentation. In other words, based on the assigned features a car can distinguish between one object and another and know their abilities and potential threats.
Still, a car has to know what each object can do and what purpose it serves on the road. As for road markings, the main things that AI needs to understand are distances to markings, yaw angle, road curvature, and road clothoid. As for pedestrians, a car can recognize the shape of a human body, patterns of movement, and a person’s location beside the road or while crossing it.
Based on the assigned features a car can distinguish between one object and another and know their abilities and potential threats.
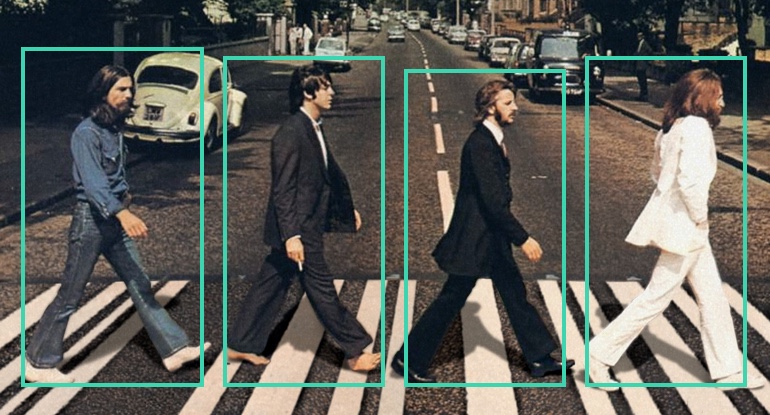
The ability to recognize an object is crucial for autonomous cars because of the complexity and diversity of driving environments. Let’s consider a situation at an intersection. A self-driving car has to interpret stationary elements like road signs, lanes, and traffic lights while at the same time responding to active objects like other cars, pedestrians, and cyclists. If a car confuses these objects or fails in vehicle detection, its reaction will be irrelevant.
Deep learning: unseen magic behind a self-driving car’s actions
Now we know what we’re seeing in the demos and videos that depict how a self-driving car sees the road and distinguishes objects using automotive computer vision for pattern recognition. This visible part covers semantic segmentation, or labeling pixels to the real environment, as well as detecting objects based on their features.
But how can a car comprehend what it has seen? Creating software that can respond to every class of object on the road and make a car act accordingly is too difficult and generates a huge volume of data. Situations on the road can be too varied and unpredictable just to collect some typical scenarios and assign reactions to them. The solution is to make cars teach themselves how to evaluate images and plan actions based on the data collected. Deep learning algorithms are exactly what’s hiding behind the scenes of computer vision and image comprehension.
Situations on the road can be too varied and unpredictable just to collect some typical scenarios and assign reactions to them. The solution is to make cars teach themselves how to evaluate images and plan actions based on the data collected.
Deep learning is a method of machine learning. It allows an in-car AI to be trained to predict outputs based on a selected set of inputs. Hidden layers placed between the input layer and the output layer create numerous correlations with possible scenarios. The more layers, the more correlations are possible. Together, these layers form a neural network.
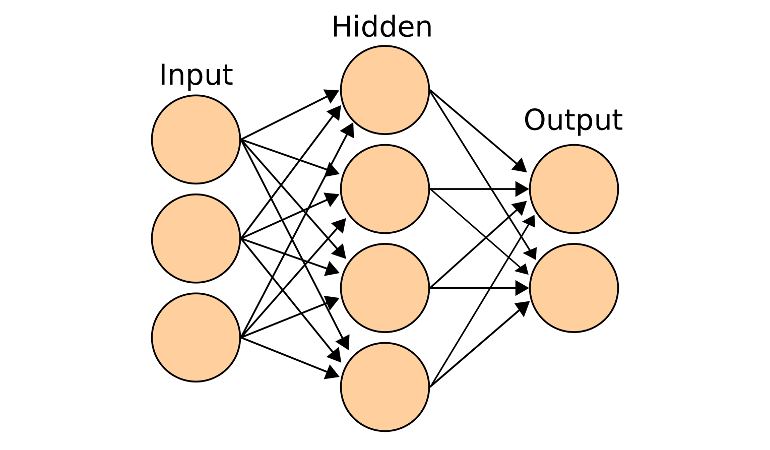
How does a neural network work?
- Each image from sensors is labeled based on the similarity of closely located pixels
- Labeled pixels are assigned with features (shape, distance, location, movement)
- Based on these features, a car’s AI detects objects
- These objects (with known features) become inputs for the neural network
- Thousands of objects and millions of features are used to train the network how to act
Further actions largely depend on how a neural network perceives each object. If a car relies only on strict categorization of objects, the algorithm will work like this:
- Receive an image with detected objects
- Analyze features of objects
- Recognize a car based on its features
- Act based on the knowledge that a car is driving ahead
The same goes for other objects such as infrastructure, pedestrians, and cyclists. This approach almost eliminates the chance of adequately reacting to objects that haven’t been categorized based on features, however. Another option is direct perception. Here’s what that looks like:
- Receive an image with detected objects
- Analyze object features
- Act as you should based on these features
As you can see, direct perception excludes the necessity of recognizing a car as a car in order to react to it accordingly. This type of detection is much more practical because of its ability to adapt to new environments based on previous training and at the same time isn’t limited by a list of objects the car can react to.
Why did the Tesla hit the fire truck?

Returning to the Tesla autopilot and fire truck incident, it’s quite possible that the car was driving on cruise control mode, which relies on ADAS subsystems that are not the same that autonomous driving at its common perception. Perhaps Tesla used the first option of object categorization. That could explain why the car didn’t recognize the fire truck. The truck isn’t a typical vehicle and it was stopped at the moment of the crash, so two main factors of detecting a car were missing. It turns out that the Tesla car didn’t have enough features to categorize the fire truck and respond to it. For this reason, the Tesla just drove straight ahead.
The truck isn’t a typical vehicle and it was stopped at the moment of the crash, so two main factors of detecting a car were missing. It turns out that the Tesla car didn’t have enough features to categorize the fire truck and respond to it. For this reason, the Tesla just drove straight ahead.
After this incident, we can’t simply say that the limits of computer vision will stop car makers from introducing fully automated vehicles that drive using passive optical sensing. It rather proves that neural networks should be trained much harder and should use direct perception of the environment instead of categorizing objects and programming assigned reactions to them.
More data on road scenarios for the purposes of AI training could be collected from simulators. For example, using a game engine, artificial intelligence may learn from its mistakes without causing real harm.
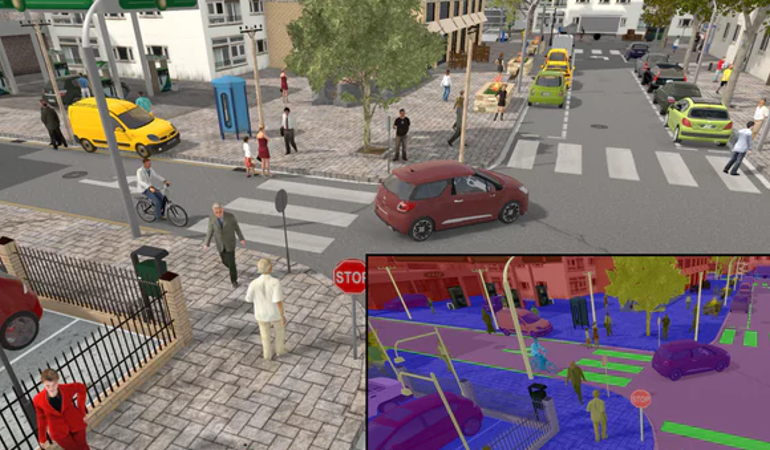
If you’re ready to use computer vision in self driving cars as the main means of vehicle automation, you should start with deep learning to train your AI to react to the real world, not only to a set of objects. If Elon Musk is brave enough to trust computer vision for autonomous driving, why aren’t you?
Ask our experts more about computer vision and how it contributes to the new world of highly automated technologies, driverless vehicles, and safer driving.



