Intelligent, self-guided, and self-driving vehicle systems are closer than you think. They may not be roaming the streets just yet, but the pace of technological advancement is pushing the advent of self-driving cars closer. The automatic system utilizes computer vision algorithms to detect and predict activity for all other traffic participants, including other vehicles, pedestrian recognition or even wild animals.
For a self-driving car, pedestrian detection is a vital feature to ensure safety. So, the main goal of the machine learning approach in the automotive domain is the possibility to predict dangerous situations on the road ahead of time. A critical benefit the system provides to the cars is distinguishing pedestrians and vehicles in motion so that they make smarter and safer driving decisions.
In this article, we go through the machine learning development services and methodologies used in autonomous vehicles, such as object detection, object segmentation and prediction to track their surroundings properly, pedestrian detection, predict object locations and possible collisions. We do not only explain how real-time pedestrian detection works in theory but also display the practical implementation of the methodologies in self-driving cars:
Real-time pedestrian presence detection with neural networks
Object tracking and its velocity prediction is a well-researched area outside the automotive industry. These are mostly conducted using computer vision and machine learning approaches.
Pedestrian recognition components
Considering the effort to build pedestrian tracking software, the research focuses on several modules (see fig. 1.):
- a pedestrian detector
- a pedestrian tracker and location predictor
- a road segmentation module
- a pedestrian collision prediction module itself
Now, let’s discuss each pedestrian location predictor in details.
Pedestrian detector
Computer vision approaches based on neural network solutions allow detecting a variety of objects with different accuracy. Most popular neural network topologies for vehicle and pedestrian detection are GoogleNet, SSD, MobileNet and YoLo, with the last one being used to build media for this article.
All these are state-of-the-art solutions for pedestrian detection in cars. But they can detect pedestrians in a single image only. Therefore, using neural networks to establish tracking and build its trajectory is not enough: additional solutions must be implemented to link the same pedestrian in two consequence images from a video sequence.
Pedestrian tracker and location predictor
In the 1960s, a set of algorithms was developed to enable motion tracking. Kalman filter and its variations were used to model Apollo spacecraft trajectories to the Moon and back. Today, these algorithms can be applied in an autonomous vehicle, too, to predict the position and velocity of approaching pedestrians. Let’s discover the specifics of the Kalman filter for pedestrian detection.
Road segmentation module
A front camera view handles the road recognition part in a self-driving car. A neural network labels the pixels of a road in images, usually by Fully Convolutional Neural Network (FCN), particularly FCN-VGG16, trained with KITTI or CityScape dataset for road segmentation. This article is based on the mentioned neural network as well.
Pedestrian collision prediction module
This module analyzes the intersection of pedestrian location prediction and the road segment. If these two objects intersect, the car and pedestrian collision has a non-zero probability, and it is a zero one in the opposite case. The collision probability depends on the direction vectors of both pedestrians and the car.
General scheme of pedestrian recognition
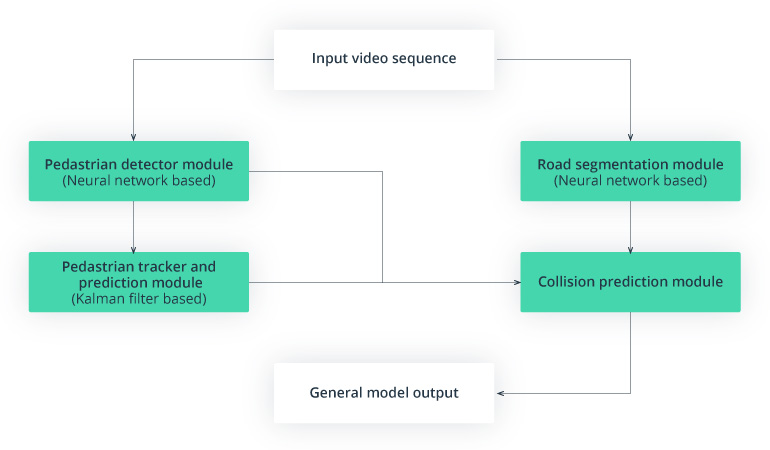
Other approaches in pedestrian detection for autonomous vehicle
While the neural network approaches for object detection and road segmentation are well-described in many scientific articles, we would like to focus on two more components in this article: Kalman Filter for pedestrian detection and Pedestrian collision prediction module.
Kalman Filter
Kalman Filter (KF) is a core component of pedestrian detection. KF implements a series of predictions and state updates which are executed as the single dataflow displayed next (fig. 2.):
General scheme of the Kalman filter
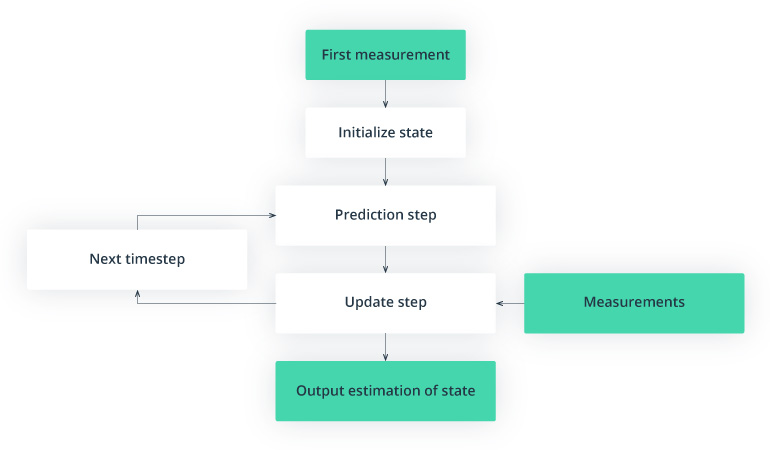
Let’s dive deeper into more details of how the Kalman filter works with the linear motion model of the tracking object, using visual image data only:
1. Prediction step
The current state Xt+1 is estimated based on the previous state Xt using motion model F (transition state matrix) and process noise v:
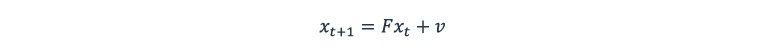
The above equation for the new state contains information about one’s position Pt and velocity Vt and can be written in a matrix form:
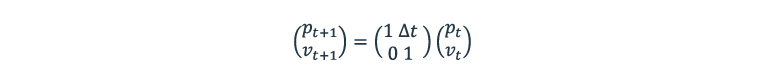
This is equivalent to the following:
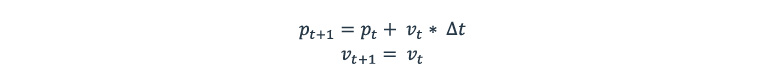
The state estimation can be described as a vector:
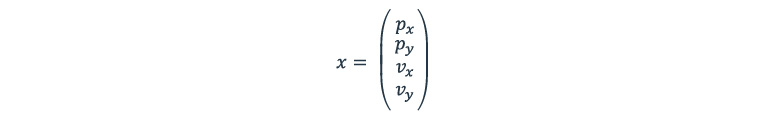
We neglect the process noise v for simplification, and we also should calculate covariance matrix Pt+1 – a measure of the estimated state accuracy – based on the covariance matrix Pt from the previous step of the Kalman filter:
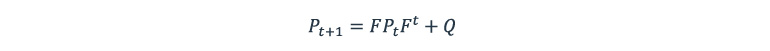
2. The update step
We are to obtain the new measurements z of the bound boxes from the pedestrian detection module and calculating measurement update y:
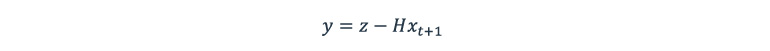
H is a transformation matrix (or measurement matrix), intended to map object detection data space into our model space.
The next step is calculating the Kalman gain (K):
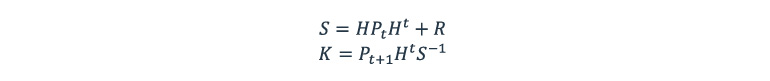
The Kalman gain basically shows what to rely on, either estimated state or detection data:
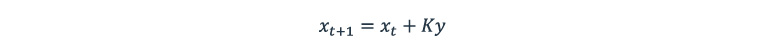
If the Kalman gain is a bigger number, sensor data will be more impactful on the calculation of the new estimated state. If it is a smaller number, we have to rely on the mathematical model of the estimated state.
The output of the Kalman filter is a fine-tuned trajectory of pedestrian direction. The prediction of pedestrian location for an extended period can be implemented by simply repeating step #1. Evidently, a long-lasting prediction will have less accuracy than a shorter one, with each new prediction step of the Kalman filter adding more uncertainty to the predicted data.
Pedestrian collision prediction module
The general approach to pedestrian detection in cars also includes pedestrian collision predictor. The module obtains raw data from the pedestrian detector, prediction data from the Kalman filter and data from the road segmentation module.
The purpose of the module is to combine all the information and analyze the interposition of a pedestrian, his/her predicted location and the location on the road. The output of the model is a probability of a car-pedestrian collision.
The following is a brief overview the module’s workflow:
1) Pedestrian step distance calculation
In the real-world conditions, information on the distance between the car and the pedestrian, along with the car speed, can be easily obtained from the vehicle’s ADAS computer. Pedestrian recognition using automotive RADAR sensor or LIDAR hardware handles distance measurement to the obstacles.
However, in this case, the information was absent, and distance d was withdrawn from geometrical calculations based on the pedestrian box’s bottom line and camera view angle in the following way (fig. 3):
Distance to the pedestrian
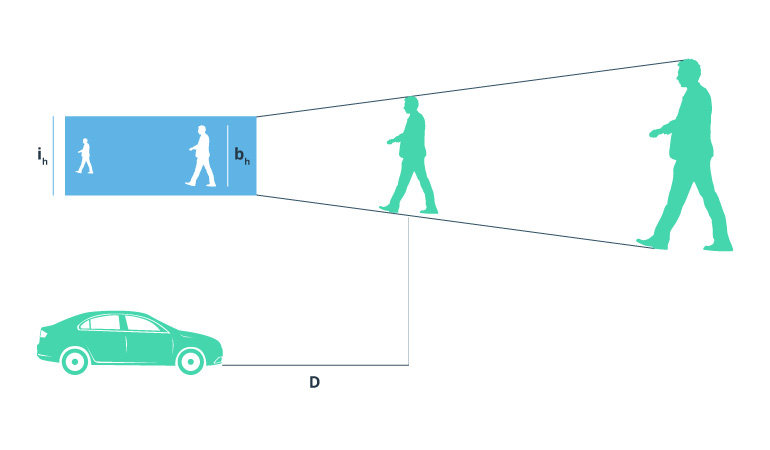
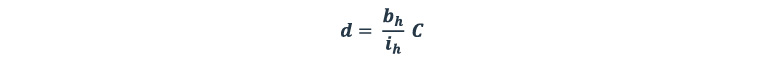
where Bh– pedestrian bound box height (predicted or detected) in pixels,
ih– image height in pixels,
C– constant calculated manually for a specific car camera (data obtained for a specific test image dataset).
For test experiment it is not important to define the absolute value of distance, it is more important to calculate the distance metric to understand how far pedestrian stands from the vehicle.
2) Collision prediction step
To calculate the collision probability, the information on the bottom coordinates of pedestrian bound boxes is required, which is predicted and obtained from the object detector and Kalman filter. The main idea of this step is to check the intersection of a road segment and box’s bottom line.
In case of an intersection, a pedestrian (or pedestrian predicted location) stands on the vehicle path, and the collision may happen.
To simplify, the collision probability was calculated as the ratio of distance to the predicted pedestrian location and general distance of detected road available for the car:

where IoU– a function showing the intersection over the union of road segment and the pedestrian predicted location bound box,
bh– pedestrian bound box height (predicted or detected) in pixels,
rh– road segment max height in pixels.
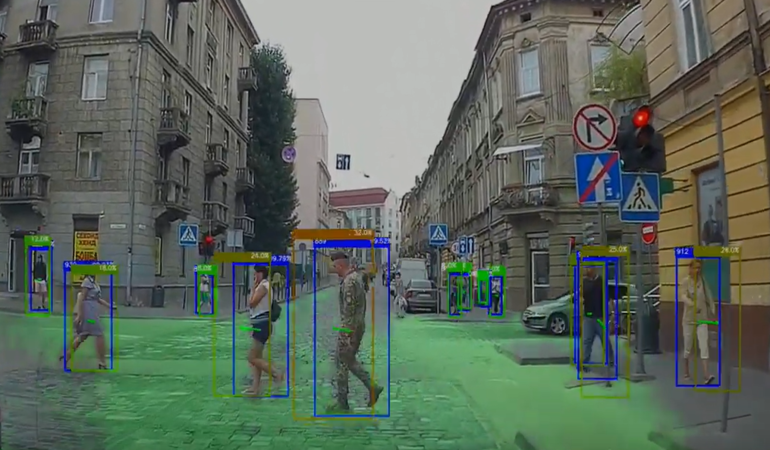
An example of the algorithm implementation is in pic.2, with the results of automatic road segmentation highlighted in green. There are confidence members for each bound box: blue bound boxes for pedestrian detection confidence and green/red bound boxes for collision probability. The box color also defines the collision probability: red – high probability, green – low probability.
The final output of pedestrian collision detector approach (blue boxes – detections, green boxes – location predictions)
Conclusion
Computer vision problem requires a solution for automotive driving, particularly pedestrian detection and tracking with moving camera. And such a solution is possible: convolutional neural network allows for robust pedestrian tracking. However, an additional challenge for advanced automotive driving is the pedestrian location prediction algorithm, which can be based on pure machine learning techniques.
In this article, we have described the main components of pedestrian detection for autonomous vehicle and reviewed the pedestrian location prediction algorithm in-depth, which is based on the Kalman filter. The result we have achieved show that the listed mathematical algorithms allow building a single approach to real-time pedestrian detection and avoid dangerous road situations in self-driving cars.
Contact our automotive experts at Intellias to learn more about the Kalman filter application for pedestrian recognition and the mathematical algorithms in autonomous vehicles.


