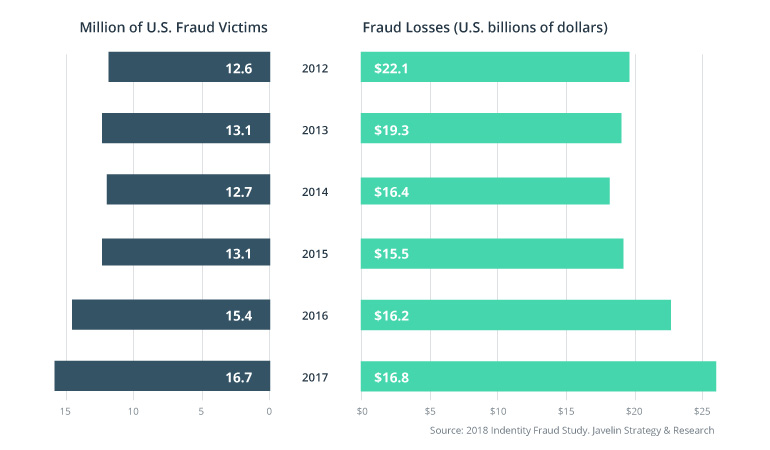
According to Infosecurity Magazine, fraud cost the global economy £3.2 trillion in 2018. For some businesses, losses to fraud reach more than 10% of their total spending. Such massive losses push companies to search for new solutions to prevent, detect, and eliminate fraud. Machine learning is the most promising technological weapon to fight financial fraud. We’ll tell everything you need to know about prospects and limitations of machine learning in fraud detection now.
In this article, you’ll learn:
- What is fraud detection?
- Why use machine learning for fraud detection?
- ML is more effective than humans
- ML handles overload well
- ML beats traditional fraud detection systems
- How does machine learning in fraud detection work?
- Fraud detection machine learning models and algorithms
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
- Reinforcement learning
- Machine learning in fraud detection: Use cases
- Final thoughts on fraud detection machine learning models

What is fraud detection?
According to the Cambridge Dictionary, fraud is “the crime of getting money by deceiving people.” It’s as old as humanity. Ever since people started exchanging goods and services, there has been a risk of one party scamming the other. And there has always been a risk of a third party scamming both the seller and the buyer. With the development and expansion of e-commerce, fraud has taken on new forms and become more powerful than ever. As the scale of e-shopping, online banking, and online insurance increases, fraudsters take full advantage of every weak spot in every system they can find. Quite often, before professionals can patch up a system, sensitive data is stolen and millions of dollars are lost. Fraud has turned into a major issue and an uncontrolled expenditure for e-commerce retailers on a global level.

Preventing, detecting, and eliminating fraud are some of the primary concerns of the e-commerce and banking industries at present. One of the most promising means for achieving them are machine learning development services.
Machine learning has already been used to successfully detect email spam. It also makes focused product recommendations for millions of online shoppers. The availability of big data allows machine learning to develop at a great scale and improve significantly over a very short time. Advances in statistical modeling and constantly increasing processing power make it possible for machine learning to enter the e-commerce and banking sectors. These industries are placing big hopes on effective fraud detection using machine learning as a tool that can prevent cyber crime. Let’s see how this goal can be achieved.
Why use machine learning for fraud detection?
In a nutshell, machine learning (ML) is the science of creating and applying algorithms that are capable of learning from the past. Machine learning finds a perfect use case in fraud detection. Machine learning algorithms learn to tell fraudulent operations from legitimate ones without raising the suspicions of those executing the transactions. Machine learning can fight financial fraud by using big data better and faster than humans ever will be able to.
Fraud detection machine learning models are more effective than humans
The concept behind using machine learning in fraud detection is that fraudulent transactions have specific features that legitimate transactions do not. Based on this assumption, machine learning algorithms detect patterns in financial operations and decide whether a given transaction is legitimate. Machine learning fraud detection algorithms are way more effective than humans. They can process a raft of information faster than a team of the best analysts ever could. What’s more, ML algorithms can spot patterns that seem unrelated or go unnoticed by a human. By exploring and studying tons of cases of fraudulent behavior, ML algorithms determine the most stealthy fraudulent patterns and remember them forever.
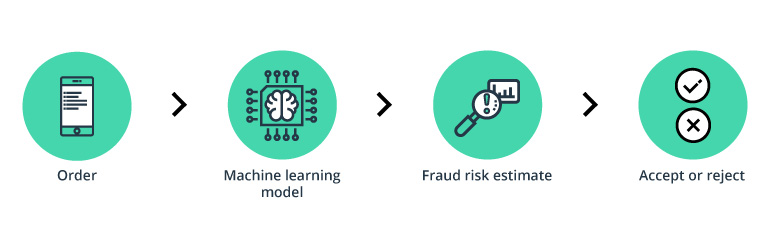
ML handles overload well
As online fraud becomes omnipresent, it also gets more sophisticated. Both fraudsters and businesses use cutting-edge technologies and race to get a step ahead. In such a stressful environment, companies need to analyze way more information than they can handle to fight fraud. Even when a business hires a team of top data scientists, they cannot chase fraudulent attempts as fast as they happen. Fraud detection machine learning models come to the rescue, being able to work 24/7 and analyze enormous amounts of data at the snap of a finger.
ML beats traditional fraud detection systems
The traditional fraud detection model is based on a static rules-based system, also referred to as a production or expert system. Although these systems have been effective for a long time, some of their major disadvantages make them unsuitable for modern digital environments. A static rules-based system is heavily dependent on human labor. But naturally, top analysts are expensive. And their work takes time. What’s more, even top experts create rules based on their knowledge, skills, and experience, which are always limited. Such rules can grow to enormous sizes and get so complex that it’s nearly impossible for an outsider to understand them when needed. Also, creating a new rule and implementing it takes a while when done by hand.
Fraud detection using machine learning can solve all of these issues. It can beat traditional fraud detection systems in terms of speed, quality, and cost-effectiveness. An unsupervised machine learning system can process new data autonomously all the time and update its models and patterns immediately. As the data assets of every business become more and more overwhelming, it becomes clear that only machine learning can cope with this volume of information. The more data ML algorithms process, the better they get and the more they learn. Eventually, more data and higher workloads mean better and more precise fraud detection algorithms.
By incorporating MLOps services into ML capabilities for fraud detection, organizations can not only deploy sophisticated machine learning models but also establish automated pipelines that facilitate ongoing model updates, scalability, and robust performance monitoring, thereby fortifying their defense against fraudulent activities in a dynamic and evolving landscape.
How does machine learning in fraud detection work?
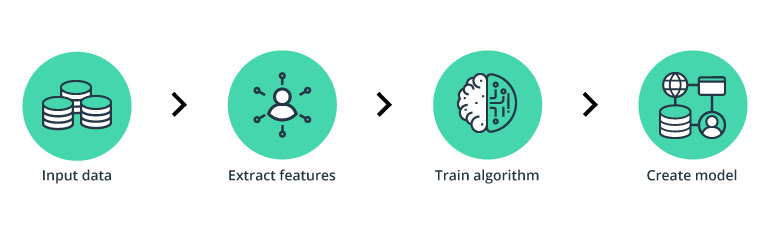
To detect fraud, a machine learning model first needs to collect data. The model analyzes all the data gathered, segments, and extracts the required features from it. Next, the machine learning model receives training sets that teach it to predict the probability of fraud. Finally, it creates fraud detection machine learning models.
The first step, data input, differs for ML and humans. Whereas humans struggle to comprehend massive amounts of data, such a task is a piece of cake for ML. The more data an ML model receives, the better it can learn and polish its fraud detection skills.
Feature extraction is the next step. At this point, features describing good customer behavior and fraudulent behavior are added. These features usually include (but are not limited to) the customer’s location, identity, orders, network, and chosen payment method. Based on the complexity of the fraud detection system, the list of investigated features can differ.
Next, a training algorithm is launched. In a nutshell, this algorithm is a set of rules that an ML model has to follow when deciding whether an operation is legitimate or fraudulent. The more data a business can provide for a training set, the better the ML model will be.
Finally, when the training is over, the company receives a fraud detection machine learning model suitable for their business. This model can detect fraud in next to no time with high accuracy. To be effective in credit card fraud detection, a machine learning model needs to be constantly improved and updated. Payment fraud detection can be eliminated for a while using ML. But sooner or later, fraudsters will come up with new tricks to game the system unless you keep it updated.
Machine learning models and algorithms for fraud detection
Machine learning algorithms come in the following types:
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
- Reinforcement learning
Supervised learning
Supervised learning is the most common way of implementing machine learning. It works for cases like fraud detection in deep learning environments in FinTech. In a supervised learning model, all input information has to be labeled as good or bad. A supervised learning model is based on predictive data analysis and is only as accurate as the training set provided for it. A major drawback of the supervised model is that it’s not able to detect fraud that was not included in the historical data set from which it learned.
Unsupervised learning
An unsupervised learning model is meant to detect anomalous behavior in cases where there is little transaction data or such data is not available at all. An unsupervised learning model continuously processes and analyzes new data and updates its models based on the findings. It learns to notice patterns and decide whether they’re parts of legitimate or fraudulent operations. Deep learning in fraud detection is usually associated with unsupervised learning algorithms.
Semi-supervised learning
Semi-supervised learning is somewhere between supervised and unsupervised learning. It works for cases where labeling information is either impossible or too expensive and requires the labor of human experts. A semi-supervised algorithm for fraud detection in deep learning stores data about important group parameters even when group membership of the unlabeled data is unknown. It does so based on the assumption that the discovered patterns can still be valuable.
Reinforcement learning
A reinforcement learning algorithm allows machines to automatically detect ideal behavior within a specified context. It constantly learns from the environment to find actions that minimize risks and maximize rewards. A reinforcement feedback signal is required for the model to learn its behavior.
Fraud detection using machine learning: Use cases
Currently, businesses work on fraud detection systems that incorporate machine learning and artificial intelligence. Using modern fraud protection systems powered by ML, many industries can keep their finances safe. There are already some fraud detection solutions for FinTech, e-commerce, banking, healthcare, online gaming, and other industries. No matter your industry, there’s always a way to benefit from AI and ML. Machine learning algorithms can process huge amounts of data and draw patterns for every business to protect it from fraud. For instance, machine learning helps online gaming businesses detect account takeovers and other scams by tracing patterns in a player’s in-game behavior.
Capgemini claims their ML fraud detection system can reduce fraud investigation time by 70% while increasing accuracy by 90%. Another ML fraud prevention solution provider, Feedzai, claims that a well-trained machine learning solution can identify and prevent 95% of all fraud while minimizing the amount of human labor required during the investigation stage.
Large corporations like Airbnb, Yelp, and Jet.com are already using AI solutions to get insights from big data and prevent issues such as fake accounts, account takeover, payment fraud, and promotion abuse. Machine learning takes care of all the dirty work of data analysis and predictive analytics and allows companies to grow and develop safe from fraud.
Final thoughts
Businesses all over the world have already started using data science to prevent financial fraud. Machine learning is currently the most promising innovative tool that can help companies prevent fraudulent operations that lead to greater losses each year. Yet apart from implementing modern fraud detection solutions, companies also need modern and secure FinTech services and custom software development services that are harder for fraudsters to manipulate. An outdated financial system is always full of loopholes tricksters can use. Luckily, machine learning has the potential to improve bank fraud detection with data analytics and help nearly every industry.



