With autonomous driving gaining steam, the data generated by connected vehicles becomes both a driver and a restraint of the automotive industry. While we cannot underestimate the importance of gathering information, its amount currently approaches 25 GB per hour for one car. And as the autonomy level grows, the number of data gigabytes exchanged between connected cars will increase even more. The flood of data like this creates a processing problem. To deal with it, both the architecture and data must become more complex. This is where multisensor fusion and data compression play a significant role in making the entire autonomous system work.
Data processing – fast and seamless – is the most critical and challenging task for automakers who strive for higher levels of autonomy. Being a trusted partner to many OEMs and Tier 1 companies, Intellias is involved in research for best hardware and software solutions that can handle data streams most efficiently. In this article, we’ll share our data expertise to unpuzzle how information travels in the autonomous vehicle and ways to optimize data using AI and deep learning.
In this article, you’ll learn about:
- Optimized datasets for machine learning
- Data compression methods
- Use of AI for sensor fusion and data compression
- Multisensor data fusion for AI-based self-driving cars
- An in-depth learning approach to data compression
- How compressed data is sent to the cloud
Creating optimized datasets for machine learning: how it works
After raw data from multiple sensors is gathered, it must be adequately processed. Keep in mind, the higher the autonomy level, the more sensors are needed. Processing consists of several stages:
- data cleaning: finding incomplete or inaccurate input and correcting mistakes in the raw sensor data by applying various rule- or model-based techniques
- data fusion: combining data from various sources, as well as the information from related databases, to ensure high-level accuracy
- data compression: reducing both storage space and the amount of transferred data by reducing redundancy, i.e., dropping duplicated or invaluable data; using different data representation and approximation techniques, i.e., transferring fewer data without losses and transferring compact models instead of raw data
It can be quite tricky to determine exactly all required and sufficient data that an autonomous car needs at each specific moment. Specific prerequisites help a vehicle’s AI work with sensors, gradually learning what data to use and when. However, prerequisites cannot be updated in real-time. It’s essential for the machine learning engine to recognize the required data for mission-critical actions and analyze it locally. Therefore, to run data processing, AI must:
- identify data in all formats (from all sensors)
- implement sensor fusion algorithms for all-encompassing analysis
- recognize data for mission-critical operations and analyze it locally
- compress non-critical data
- schedule the uploading of compressed data to the cloud when less critical communications are available
- call for legacy data from the cloud when the analysis of non-critical data is needed
To run the processing like this, autonomous cars have to possess powerful and, therefore, expensive machine learning engines. But to enter the mass market, automakers must look at ways to optimize data and reduce the vehicle price. To reach this goal, advanced data compression, and data fusion techniques are required, as well as efficient two-way communication between vehicle and cloud backend.
Using AI for sensor fusion and data compression
Since an AI-based autonomous car has multiple sensors – cameras, sonars, LIDAR, etc. – techniques for both fusing and compressing the arrays of connected car data gathered must be adopted. It’s a vicious cycle: for an autonomous car to function seamlessly, it needs tons of input, which requires hefty computational processing and more processors, together with more storage inside the car. It adds cost, weight, and complexity to the vehicle’s AI system. How can this be dealt with?
After fusing the data from several IoT devices, you’ll receive a large amount of information pushed forward into the system for AI to then analyze. To deal with this amount of data, various compression techniques are used. With the help of these techniques, information is encoded and undergoes compression, then decoded and uncompressed for use. There are so-called lossless compression and lossy compression approaches: in the first case, you get back all the information originally held while in the second case, some data is lost.
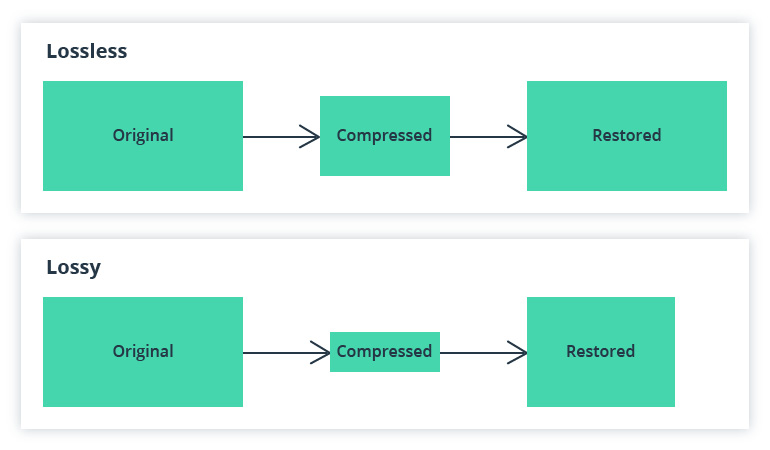
The data must be compressed at the fusion center to preserve the communication bandwidth and processing capability.
Explaining multisensor data fusion for AI-based self-driving cars
Let’s revisit sensor fusion and its importance.Sensor fusion presupposes merging data from various sources to develop an accurate and comprehensive perception. Sensor fusion is critical for a vehicle’s AI to make intelligent and accurate decisions.
Sensor fusion in an autonomous vehicle
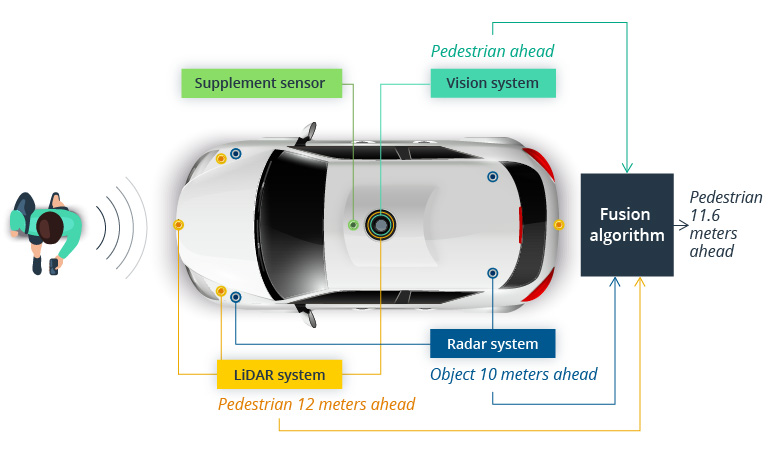
Source: Towards Data Science
Multisensor data fusion can be both homogeneous – data coming from similar sensors, and heterogeneous – data combined from different kinds of sensors based on its time of arrival. There are also different levels on which multisensor data fusion can be performed:
- signal level: on this level, the fusion creates a new signal of better quality
- object level: object-based fusion generates a fused image where each signal data type is determined with the help of clustering
- feature level: fusion on this level requires the recognition of objects from different data sources
- decision level: fusion on this level requires the combination of results from multiple algorithms
At the moment, automakers are using both the feature and decision level multisensor data fusion. However, this is not enough to reach a higher level of autonomy. For an extended sense of environment and better contextual input, signal-based fusion techniques must be adopted.
This fuels a second challenge: the more complicated processing AI has to fulfill, the more power it requires. A self-driving car needs more processors and memory onboard, which results in added cost and bigger energy consumption. What is even more critical, fusing and interpreting data from so many different sensors will take more time, and the AI reaction cannot be altered on the road. That’s why data compression is no less vital for autonomous vehicles than fusion.
Investigating data compression methods
Sensors differ in the types and volume of data they generate. Looking at the estimates given by Stephen Heinrich from Lucid Motors, the difference can be quite drastic:
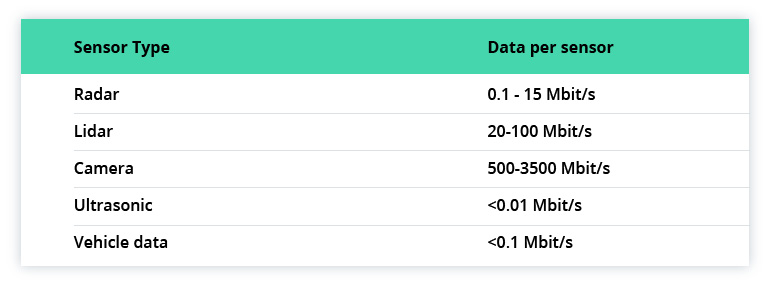
With cameras consuming the biggest part of the data exchange channel, it is the first candidate for compression. Video and LIDAR data compression can be lossless and lossy, as mentioned before. Let’s elaborate a bit.
How Intellias employs a deep learning approach to data compression
Lossless compression methods solve two key problems:
- Approximating the true data distribution to the model.
- Developing a practical compression algorithm called an entropy coding scheme.
We can approximate the expected efficiency of lossless video coding from the compression ratio of 100 images from ImageNet:
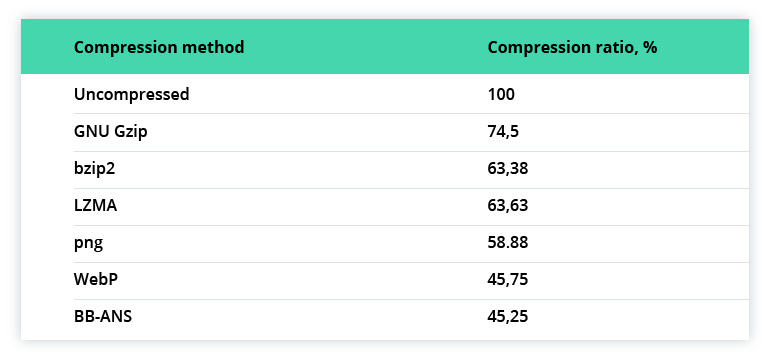
As for LIDAR, data compression approaches are:
- ilLASCompression
- LASZip
- LZMA or Lempel-Ziv-Markov chain algorithm
- Compressing POINT10
To improve data compression, we implement deep learning techniques. The recent BB-ANS method utilizes latent variable models. This model defines unobserved, random variables used to represent the distribution of original data. For example, in the case of images, pixel distribution may be dependent on the location of edges and textures, which are the latent variables.
As for lossy compression approaches, unsupervised learning methods are implemented for image modeling. We use Variational Autoencoders (VAEs), PixelCNN, and PixelRNN models to learn about latent image representation. In this case, a smaller encoded vector is exchanged and then decoded.
To separate valuable and quickly changing information from less valuable and more static, a combination of lossy and lossless approaches is implemented. When we want to optimize data, we use a lossless approach to transfer and compress larger amounts of highly dynamic and critical information. Less precise but more compact data transfers will be applied to images that are describing static surroundings or non-critical backgrounds.
Backgrounds, in turn, open possibilities for applying deep learning models for object detection and tracking. In this case, objects of interest are transferred in higher quality and rate, while everything else remains in lower quality.
Other deep learning methods for sensor data compression include attention models, which are used to reduce data size and point out the most valuable information, and Golomb-Rice encoding, a specific data compression method based on entropy, volatility/persistence, diversity/uniformity, initial data size, etc. These methods are considered lossy compression and generally refer to multidimensional scaling. They are efficient for numeric multidimensional data.
While even simple approaches to data compression can provide significant bandwidth savings, advanced ML-augmented dimensionality reduction is even more promising. With this reduction, the size of transferred data between connected cars is cut in half. Also, when coded or compressed information is sent to the cloud, the transfer data size is also reduced up to two times.
Sending compressed data to the cloud
Non-critical data, i.e., long reaction time reference data, which is not processed locally, is compressed and sent to the cloud. The cloud platform used for data storage must be capable of hosting the arrays of generated data. Computing costs are rarely mentioned when it comes to autonomous vehicles, but they should be taken into account: GM, for instance, spent $288 million for two new warehouses to store and process car data.
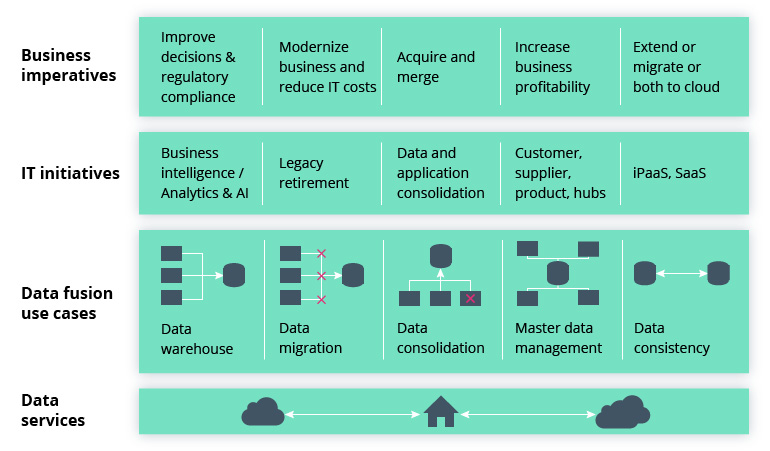
This is where products like Google’s Cloud Data Fusion solution come in handy. With this solution’s help, data from different sources can be fused into the central data warehouse. Fusion cloud allows building data pipelines and transforming them without writing any code.
Challenges Cloud Data Fusion Solves
Source: Fourcast
Intellias automotive experts use this solution as the backbone for data analytics, as well as the development and running of big data applications.
Summing it up
Sensor fusion, as well as data compression, are critical topics to the automotive industry that is heading towards higher levels of autonomy. To reach level three and beyond, autonomous vehicles must use a multitude of sensors – and the flood of data they produce. For this to happen, data processes should be optimized from the stage of generation to the stage of storage and monetization of non-critical insights. High-tech companies like Intellias use deep learning techniques to improve data compression, as well as work to pinpoint the most efficient ways of multisensor fusion. All this is aimed at helping OEMs make autonomous vehicles cheaper and, therefore, more available to the mass market.
To find out more about Intellias contribution to the development of self-driving cars, contact our automotive expert.


